type WatchClient interface { // Watch watches for events happening or that have happened. Both input and output // are streams; the input stream is for creating and canceling watchers and the output // stream sends events. One watch RPC can watch on multiple key ranges, streaming events // for several watches at once. The entire event history can be watched starting from the // last compaction revision. Watch(ctx context.Context, opts ...grpc.CallOption) (Watch_WatchClient, error) }
case <-stream.Context().Done(): err = stream.Context().Err() // the only server-side cancellation is noleader for now. if err == context.Canceled { err = rpctypes.ErrGRPCNoLeader } }
mu sync.Mutex // guards fields below it // nextID is the ID pre-allocated for next new watcher in this stream // 当客户端未指定watch id时,会用next id自动分配一个id nextID WatchID closed bool cancels map[WatchID]cancelFunc watchers map[WatchID]*watcher }
// Watch creates a new watcher in the stream and returns its WatchID. func(ws *watchStream)Watch(id WatchID, key, end []byte, startRev int64, fcs ...FilterFunc)(WatchID, error) { // prevent wrong range where key >= end lexicographically // watch request with 'WithFromKey' has empty-byte range end // key的字母序不能大于等于end iflen(end) != 0 && bytes.Compare(key, end) != -1 { return-1, ErrEmptyWatcherRange }
ws.mu.Lock() defer ws.mu.Unlock() if ws.closed { return-1, ErrEmptyWatcherRange }
if id == AutoWatchID { for ws.watchers[ws.nextID] != nil { ws.nextID++ } id = ws.nextID ws.nextID++ // 校验watch id不能重复 } elseif _, ok := ws.watchers[id]; ok { return-1, ErrWatcherDuplicateID }
w, c := ws.watchable.watch(key, end, startRev, id, ws.ch, fcs...)
ws.cancels[id] = c ws.watchers[id] = w return id, nil }
func(ws *watchStream)Cancel(id WatchID)error { ws.mu.Lock() cancel, ok := ws.cancels[id] w := ws.watchers[id] ok = ok && !ws.closed ws.mu.Unlock()
if !ok { return ErrWatcherNotExist } // 调用创建watch请求时指定的cancel回调函数进行event清理工作 cancel()
ws.mu.Lock() // The watch isn't removed until cancel so that if Close() is called, // it will wait for the cancel. Otherwise, Close() could close the // watch channel while the store is still posting events. if ww := ws.watchers[id]; ww == w { delete(ws.cancels, id) delete(ws.watchers, id) } ws.mu.Unlock()
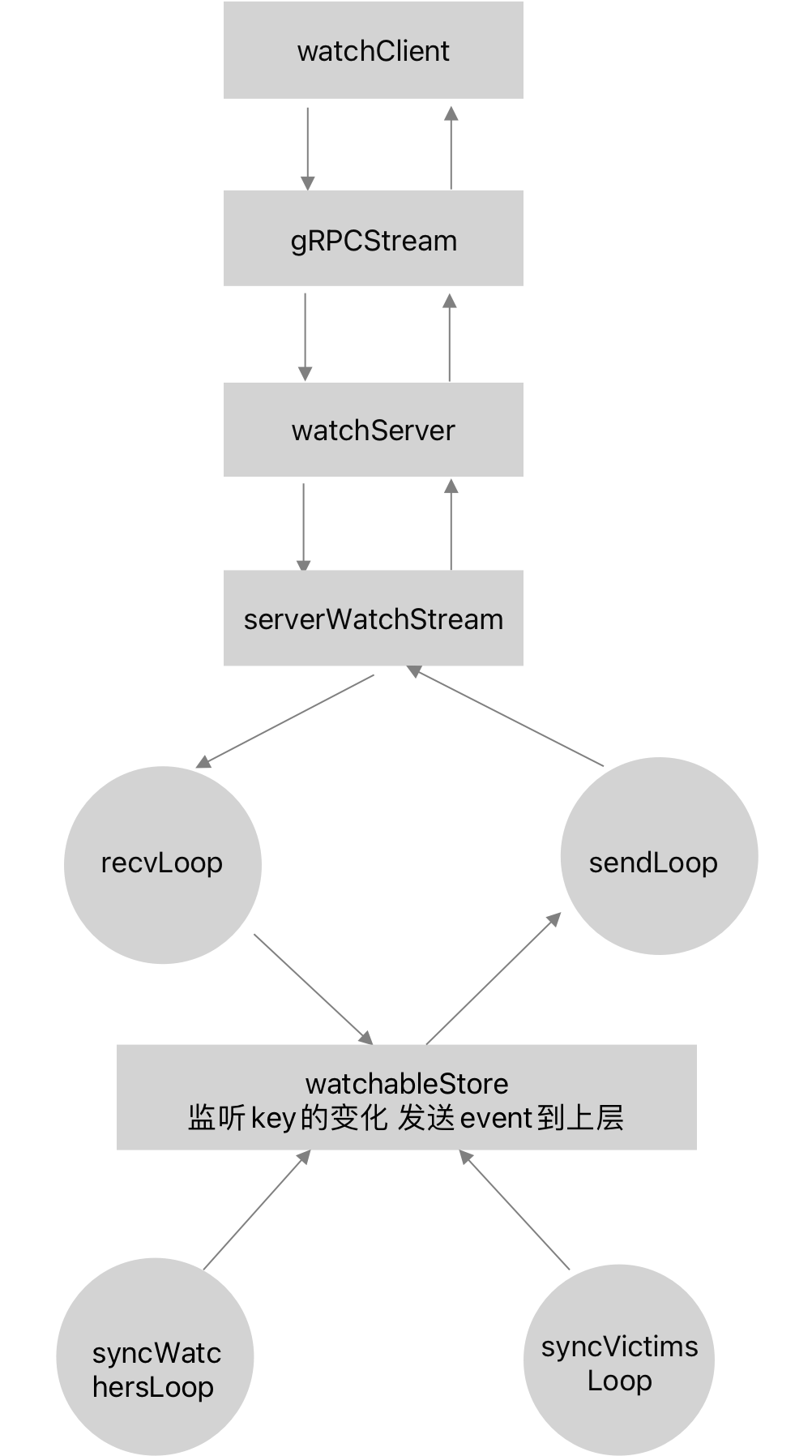
func(sws *serverWatchStream)recvLoop()error { for { req, err := sws.gRPCStream.Recv() if err == io.EOF { returnnil } if err != nil { return err } switch uv := req.RequestUnion.(type) { // 查询watch请求进度,返回当前的revision case *pb.WatchRequest_ProgressRequest: if uv.ProgressRequest != nil { sws.ctrlStream <- &pb.WatchResponse{ Header: sws.newResponseHeader(sws.watchStream.Rev()), WatchId: -1, // response is not associated with any WatchId and will be broadcast to all watch channels } } default: // we probably should not shutdown the entire stream when // receive an valid command. // so just do nothing instead. continue } } }
func(sws *serverWatchStream)sendLoop() { // watch ids that are currently active ids := make(map[mvcc.WatchID]struct{}) // watch responses pending on a watch id creation message pending := make(map[mvcc.WatchID][]*pb.WatchResponse)
// 记录metrics数据,并做一些清理工作 deferfunc() { progressTicker.Stop() // drain the chan to clean up pending events for ws := range sws.watchStream.Chan() { mvcc.ReportEventReceived(len(ws.Events)) } for _, wrs := range pending { for _, ws := range wrs { mvcc.ReportEventReceived(len(ws.Events)) } } }()
// sendLoop监听两个channel // 1、创建/取消watch时的返回信息 ctrlStream // 2、新产生的事件 sws.watchStream.Chan() for { select { case wresp, ok := <-sws.watchStream.Chan(): if !ok { return }
// TODO: evs is []mvccpb.Event type // either return []*mvccpb.Event from the mvcc package // or define protocol buffer with []mvccpb.Event. evs := wresp.Events events := make([]*mvccpb.Event, len(evs)) sws.mu.RLock() needPrevKV := sws.prevKV[wresp.WatchID] sws.mu.RUnlock() for i := range evs { events[i] = &evs[i] if needPrevKV { opt := mvcc.RangeOptions{Rev: evs[i].Kv.ModRevision - 1} r, err := sws.watchable.Range(evs[i].Kv.Key, nil, opt) if err == nil && len(r.KVs) != 0 { events[i].PrevKv = &(r.KVs[0]) } } }
if _, okID := ids[wresp.WatchID]; !okID { // buffer if id not yet announced wrs := append(pending[wresp.WatchID], wr) pending[wresp.WatchID] = wrs continue }
mvcc.ReportEventReceived(len(evs))
sws.mu.RLock() fragmented, ok := sws.fragment[wresp.WatchID] sws.mu.RUnlock()
var serr error // 判断是否需要分段发送 if !fragmented && !ok { serr = sws.gRPCStream.Send(wr) } else { serr = sendFragments(wr, sws.maxRequestBytes, sws.gRPCStream.Send) } ... sws.mu.Lock() iflen(evs) > 0 && sws.progress[wresp.WatchID] { // elide next progress update if sent a key update sws.progress[wresp.WatchID] = false } sws.mu.Unlock() } } }
// watcherGroup is a collection of watchers organized by their ranges type watcherGroup struct { // 单个key对应的watcher // keyWatchers has the watchers that watch on a single key keyWatchers watcherSetByKey // ranges has the watchers that watch a range; it is sorted by interval // 区间对应的watcher ranges adt.IntervalTree // watchers is the set of all watchers watchers watcherSet }
funcnewWatchableStore(lg *zap.Logger, b backend.Backend, le lease.Lessor, as auth.AuthStore, ig ConsistentIndexGetter, cfg StoreConfig) *watchableStore { s := &watchableStore{ store: NewStore(lg, b, le, ig, cfg), victimc: make(chanstruct{}, 1), unsynced: newWatcherGroup(), synced: newWatcherGroup(), stopc: make(chanstruct{}), } s.store.ReadView = &readView{s} s.store.WriteView = &writeView{s} if s.le != nil { // use this store as the deleter so revokes trigger watch events s.le.SetRangeDeleter(func()lease.TxnDelete { return s.Write(traceutil.TODO()) }) } if as != nil { // TODO: encapsulating consistentindex into a separate package as.SetConsistentIndexSyncer(s.store.saveIndex) } s.wg.Add(2) // 每100ms处理unsynced的请求 go s.syncWatchersLoop() // 处理victim也就是阻塞的事件 go s.syncVictimsLoop() return s }
// in order to find key-value pairs from unsynced watchers, we need to // find min revision index, and these revisions can be used to // query the backend store of key-value pairs curRev := s.store.currentRev compactionRev := s.store.compactMainRev
// moveVictims tries to update watches with already pending event data func(s *watchableStore)moveVictims()(moved int) { s.mu.Lock() victims := s.victims s.victims = nil s.mu.Unlock()
var newVictim watcherBatch for _, wb := range victims { // try to send responses again // 尝试继续发送阻塞的事件 for w, eb := range wb { // watcher has observed the store up to, but not including, w.minRev rev := w.minRev - 1 if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: rev}) { pendingEventsGauge.Add(float64(len(eb.evs))) } else { if newVictim == nil { newVictim = make(watcherBatch) } newVictim[w] = eb continue } moved++ }
rev := tw.Rev() + 1 evs := make([]mvccpb.Event, len(changes)) for i, change := range changes { evs[i].Kv = &changes[i] if change.CreateRevision == 0 { evs[i].Type = mvccpb.DELETE evs[i].Kv.ModRevision = rev } else { evs[i].Type = mvccpb.PUT } }
// end write txn under watchable store lock so the updates are visible // when asynchronous event posting checks the current store revision tw.s.mu.Lock() // 通知watch有新的事件产生 tw.s.notify(rev, evs) tw.TxnWrite.End() tw.s.mu.Unlock() }